1.1 인공 지능과 머신 러닝, 딥러닝

인공 지능 -> "컴퓨터가 '생각'할 수 있는가?"라는 질문을 하면서 시작
인공지능의 간결한 정의: 보통의 사람이 수행하는 지능적인 작업을 자동화하기 위한 연구 활동
심볼릭 AI: 프로그래머들이 명시적인 규칙을 충분하게 많이 만들어 데이터베이스에 저장된 지식을 다루면 인간 수준의 인공 지능을 만드는 접근 방법
- 이미지 분류, 음성 인식, 언어 번역 같은 더 복잡하고 불분명한 문제를 해결하기 위한 명확한 규칙을 찾는 것은 아주 어려운 일
- 이런 심볼릭 AI를 대체하기 위한 새로운 방법이 바로 머신러닝

머신 러닝 시스템은 명시적으로 프로그램되는 것이 아니라 훈련(training)
머신 러닝을 하기 위해서는 세 가지가 필요함
- 입력 데이터 포인트
- 기대 출력
- 알고리즘의 성능을 측정하는 방법
측정값은 알고리즘의 작동 방식을 교정하기 위한 신호로 다시 피드백
이런 수정 단계를 학습(learning)이라고 함
머신러닝에서 학습(learning): 유용한 데이터 표현을 만드는 데이터 변환을 피드백 신호를 바탕으로 자동으로 탐색하는 과정
딥러닝
- 딥러닝은 머신 러닝의 특정한 한 분야로서 연속된 층(layer)에서 점진적으로 의미 있는 표현을 배우는 데 강점이 있으며, 데이터로부터 표현을 학습하는 새로운 방식
- 딥러닝의 딥(deep)이란 단어가 어떤 깊은 통찰을 얻을 수 있다는 것을 의미하지는 않음
- 데이터로부터 모델을 만드는 데 얼마나 많은 층을 사용했는지가 그 모델의 깊이가 됨
- 이 분야에 대한 적절한 다른 이름은 층 기반 표현 학습(layered representations learning)또는 계층적 표현 학습(hierarchial representations learning)이 될 수 있음
- 1~2개의 데이터 표현 층을 학습하는 방식 -> 얕은 학습(shallow learning)
- 딥러닝에서는 말 그대로 층을 겹겹이 쌓아 올려 구성한 신경망(neural network)이라는 모델을 사용하여 층 기반 표현을 학습

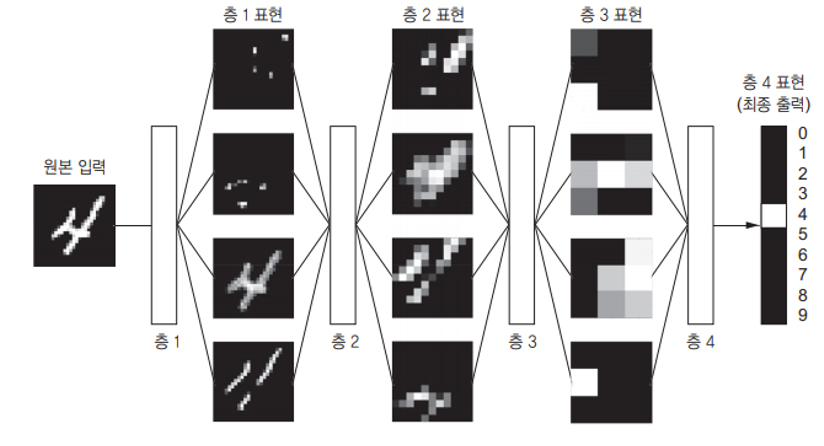
딥러닝의 작동 원리 이해하기
- 층이 입력 데이터를 처리하는 방식은 일련의 숫자로 이루어진 층의 가중치(weight)에 저장되어 있음
- 기술적으로 말하면 어떤 층에서 일어나는 변환은 그 층의 가중치를 파라미터(parameter)로 가지는 함수로 표현
- 이런 맥락으로 보면 학습은 주어진 입력을 정확한 타깃에 매핑하기 위해 신경망의 모든 층에 있는 가중치 값을 찾는 것을 의미

- 신경망의 출력을 제어하려면 출력이 기대하는 것보다 얼마나 벗어났는지 측정. 이는 신경망의 손실함수(loss function)가 담당하는 일
- 손실 함수를 이따금 목적 함수(objective function) 또는 비용 함수(cost function)라고도 부름

- 점수를 피드백 신호로 사용하여 현재 샘플의 손실 점수가 감소되는 방향으로 가중치 값을 조금씩 수정하는 것. 이런 수정 과정은 딥러닝의 핵심 알고리즘인 역전파(backpropagation) 알고리즘을 구현한 옵티마이저(optimizer)가 담당

- 네트워크가 모든 샘플을 처리하면서 가중치가 조금씩 올바른 방향으로 조정되고 손실 점수가 감소. 이를 훈련 반복(training loop)이라고 하며, 충분한 횟수만큼 반복하면(일반적으로 수천 개의 샘플에서 수십 번 반복하면)손실 함수를 최소화하는 가중치 값을 산출
'인공지능[AI]' 카테고리의 다른 글
| 케라스 창시자에게 배우는 딥러닝[5장: 머신 러닝의 기본 요소] (0) | 2023.07.20 |
|---|---|
| 케라스 창시자에게 배우는 딥러닝[4장: 신경망 시작하기: 분류와 회귀] (0) | 2023.07.18 |
| 케라스 창시자에게 배우는 딥러닝[3장: 케라스와 텐서플로 소개] (0) | 2023.07.17 |
| 케라스 창시자에게 배우는 딥러닝 [2장: 신경망의 수학적 구성 요소] (0) | 2023.07.14 |
| 머신러닝이란?(Machine Learning) (0) | 2023.03.02 |



